
JavaScript errors from search engine spiders and web crawlers have become increasingly common as these bots attempt to execute JavaScript to better understand modern web applications. These automated systems use simplified JavaScript engines that frequently encounter errors when processing complex client-side code.
While search engines like Google have improved their JavaScript execution capabilities, crawler technology still lags behind modern browsers, resulting in unpredictable failures that generate noise in error monitoring systems.
Important: These errors typically represent limitations in crawler technology rather than problems with your application that affect real users.
The Problem
Search engine spiders and web crawlers generate JavaScript errors when their simplified JavaScript engines encounter code patterns, APIs, or browser features that they don’t fully support. These errors appear in your monitoring systems as if they were user-facing issues, but they actually originate from automated bots indexing your site.
Common crawlers that generate JavaScript errors include:
- Googlebot - Google’s web crawler
- Baiduspider - Baidu’s search engine crawler
- AhrefsBot - SEO analysis crawler
- facebookexternalhit - Facebook’s link preview crawler
- HeadlessChrome - Automated testing and crawling tool
- YandexBot - Yandex search engine crawler
- ClaudeBot - Anthropic’s web crawler
- WebPageTest.org - Website performance and scanning service
These crawlers execute JavaScript to understand dynamic content, but their engines lack the sophistication and completeness of modern browsers like Chrome, Firefox, or Safari.
Key point: Crawler errors indicate bots attempting to index your content, not actual user experience problems requiring immediate fixes.
Understanding the Root Cause
JavaScript errors from spiders and crawlers stem from fundamental differences between crawler technology and user browsers:
1. Simplified JavaScript Engines
Primary cause: Crawlers use basic JavaScript engines that don’t implement all modern browser APIs, causing errors when encountering unsupported features.
How to identify: Errors from user agents containing “bot”, “spider”, “crawler”, or specific crawler names like “Googlebot”.
2. Missing Browser APIs
Crawlers often lack implementations for DOM APIs, web storage, geolocation, notifications, and other browser-specific features that modern web applications rely on.
How to identify: Errors related to undefined methods or properties that would normally exist in browsers.
3. Incomplete CSS and Rendering Support
Search engine crawlers may not fully render CSS or handle complex layout calculations, causing JavaScript that depends on element dimensions or positioning to fail.
How to identify: Errors related to layout calculations, scroll positions, or element measurements.
4. Timing and Asynchronous Operation Issues
Crawlers may not handle asynchronous operations, promises, or complex timing scenarios the same way browsers do.
How to identify: Errors related to timeouts, race conditions, or asynchronous API calls.
5. Third-Party Script Incompatibilities
External scripts (analytics, advertising, social widgets) often fail completely in crawler environments that don’t support their requirements.
How to identify: Errors originating from third-party domains or libraries in crawler user agents.
How to Fix Spider and Crawler Errors
Quick Troubleshooting Checklist
- Identify which crawlers are generating errors in your monitoring
- Verify your site’s core content is accessible without JavaScript
- Configure error monitoring to filter out known crawler user agents
- Implement server-side rendering for critical SEO content
- Consider if crawler errors indicate SEO accessibility issues
- Set up ignore rules for crawler-generated noise
The primary approach is filtering crawler noise while ensuring your content remains accessible:
Step 1: Identify Crawler Traffic
You can quickly identify the the kinds of crawlers and bots visiting your site by paging through the TrackJS Browser report. It will show you all the different bots, versions, and how many errors they encountered. Here’s an example.
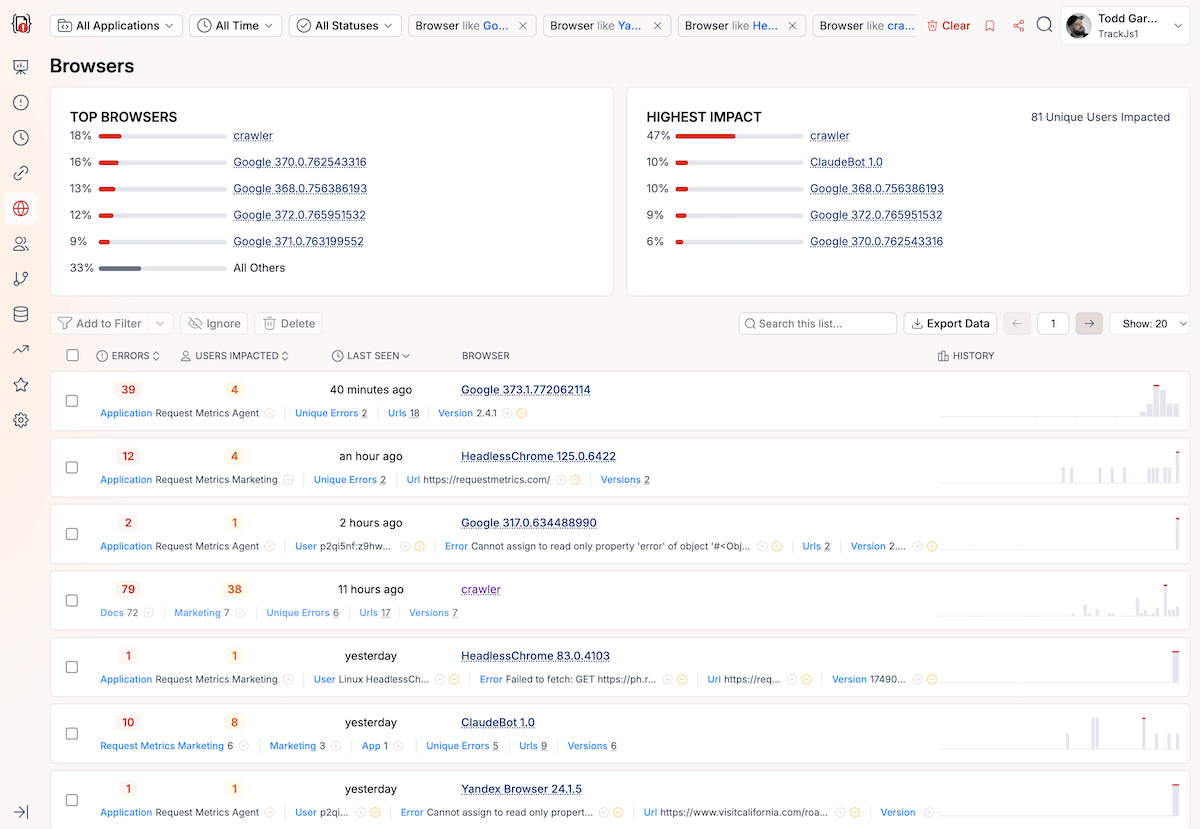
Step 2: Configure Error Monitoring Filters
Set up ignore rules to filter out crawler-generated errors. This is really easy to do without changing your code with a TrackJS Ignore rule.
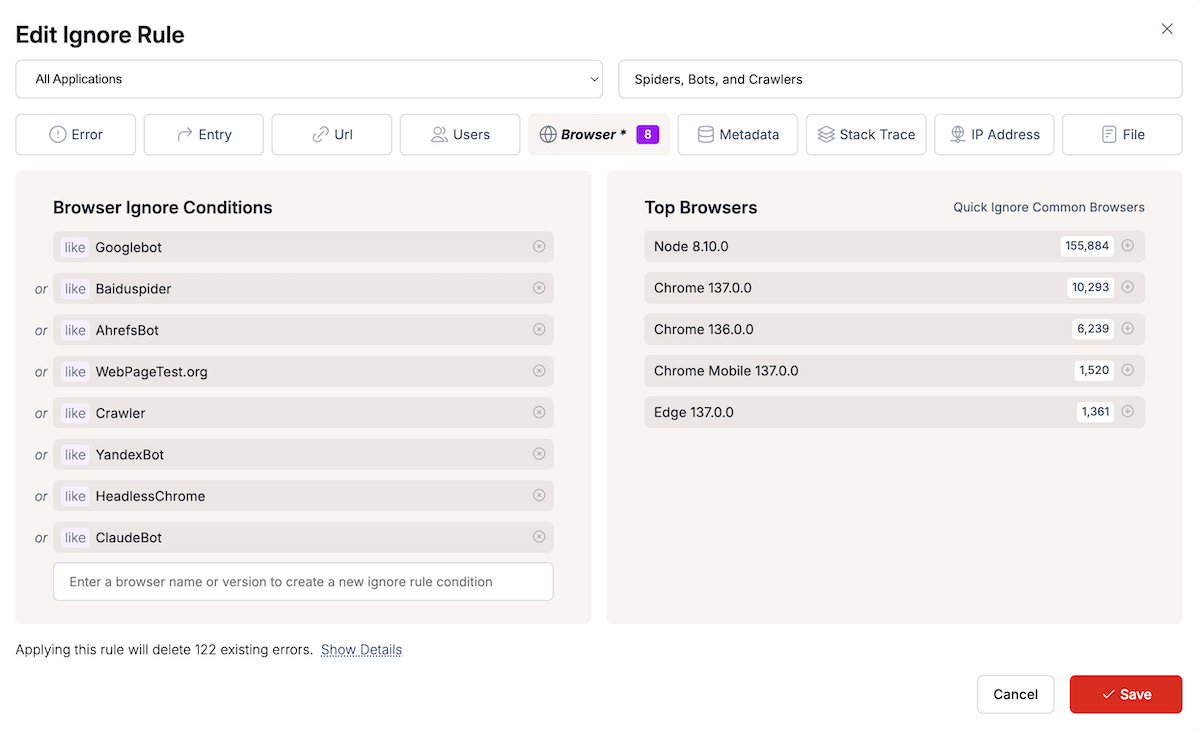
TrackJS Ignore Rule Configuration:
- User Agent contains:
googlebotORbaiduspiderORahrefsbotORfacebookexternalhit - Additional patterns:
headlesschrome,yandexbot,claudebot,webpagetest
If you prefer to change the behavior of your site for crawlers, you can implement a basic check in your JavaScript.
function isBot() {
const userAgent = payload.metadata.userAgent.toLowerCase();
const crawlerIndicators = [
'googlebot', 'baiduspider', 'ahrefsbot', 'facebookexternalhit',
'headlesschrome', 'yandexbot', 'claudebot', 'webpagetest',
'bingbot', 'slurp', 'duckduckbot', 'applebot', 'twitterbot'
];
return crawlerIndicators.some(indicator => userAgent.includes(indicator));
}
Step 3: Implement Crawler-Safe Code Patterns
Write defensive JavaScript that handles missing APIs gracefully:
// Safe feature detection for crawler environments
function safeFeatureDetection() {
// Check for localStorage availability
const hasLocalStorage = (() => {
try {
const test = 'test';
localStorage.setItem(test, test);
localStorage.removeItem(test);
return true;
} catch (e) {
return false;
}
})();
// Check for geolocation API
const hasGeolocation = 'geolocation' in navigator;
// Check for intersection observer
const hasIntersectionObserver = 'IntersectionObserver' in window;
return {
localStorage: hasLocalStorage,
geolocation: hasGeolocation,
intersectionObserver: hasIntersectionObserver
};
}
// Graceful degradation for crawlers
function initializeForEnvironment() {
const features = safeFeatureDetection();
const isCrawlerEnv = isBot();
if (isCrawlerEnv) {
console.log('Crawler environment detected - using basic initialization');
initializeBasicFeatures();
} else {
console.log('Browser environment - full initialization');
if (features.localStorage) initializeWithStorage();
if (features.geolocation) initializeLocationFeatures();
if (features.intersectionObserver) initializeLazyLoading();
}
}
Step 4: Ensure SEO-Critical Content Accessibility
Usually the only thing that bots and crawlers need to consume is the main content of the page. So you need to make sure that the content is available, even when everything else doesn’t load correctly.
Step 5: Monitor Crawler Error Patterns
Track crawler error trends to identify potential SEO impacts. Error monitoring services like TrackJS can help you distinguish between harmless crawler noise and genuine accessibility issues that might affect your search engine rankings.
While filtering crawler errors from alerts, monitoring their volume can indicate when major crawlers update their JavaScript engines or encounter new compatibility issues.
When to Ignore Crawler Errors
Crawler and spider errors should usually be ignored because:
- Technology limitations: Crawlers use simplified JavaScript engines by design
- No user impact: Crawler errors don’t affect actual user experience
- High noise volume: Can generate significant error volume without indicating real problems
- Unpredictable behavior: Crawler JavaScript execution is inherently unstable
However, investigate further if:
- SEO performance declines: Search rankings drop coinciding with crawler errors
- Content accessibility issues: Critical content requires JavaScript to be visible
- Structured data problems: JavaScript-dependent metadata isn’t being indexed
- Core functionality errors: Crawler errors indicate broader JavaScript reliability issues
Summary
Search engine spiders and web crawlers generate JavaScript errors due to their simplified JavaScript engines that lack the sophistication of modern browsers. These errors typically represent limitations in crawler technology rather than user-facing problems.
The appropriate response is filtering crawler errors from your monitoring system while ensuring that SEO-critical content remains accessible when JavaScript fails. Focus on progressive enhancement and server-side rendering for content that search engines need to index.
Remember: Crawler errors are a normal part of the modern web where search engines attempt to execute JavaScript with limited capabilities. The key is distinguishing between harmless crawler noise and genuine accessibility issues that could impact SEO performance.
