

Until recently, a client-side web-application couldn’t care about SEO. You probably still shouldn’t use it for SEO. The spiders that Google uses to index content didn’t know how to handle the complexities of Angular or Ember. When Googlebot came along, it expected your best stuff; not an empty DOM.
If you needed SEO for a JavaScript Application, you had three choices:
- Don’t use client-side rendering on the indexed content
- Build a second version of your system that serves spiders
- Use Isomorphic “fronty-backy” JavaScript and render on the server
All of these options create multiple application paths that do not always justify their cost in complexity over using other traditional server-rendered stacks.
Good news for SEO on AngularJS sites!
Brad Green, AngularJS
In May of 2014, Google announced that they would execute JavaScript when indexing pages. There was a lot of excitement about this: web applications could now consider client-side rendering without losing their SEO. A whole new segment for JavaScript opened.
Eighteen months later, we wanted to crunch some data and see how Googlebot stacks up on errors.
Just over 20% of our customers capture errors from the Googlebot browser. Considering individual applications, Googlebot has different failure modes than Chrome. That is, we see different errors at different stages in execution from the two browsers. Worse, Googlebot doesn’t seem to send a stack trace along with its errors! This is very concerning to us: how do we begin to debug Googlebot issues if we can’t debug the browser?
Anecdotally, we also see a higher failure rate in Googlebot’s JavaScript than other modern browsers.
Googlebot also appears to vary its user agent when indexing a page. About 15% of the time, it emulates a mobile browser when crawling, presumably to verify the mobile content meets their new standards.
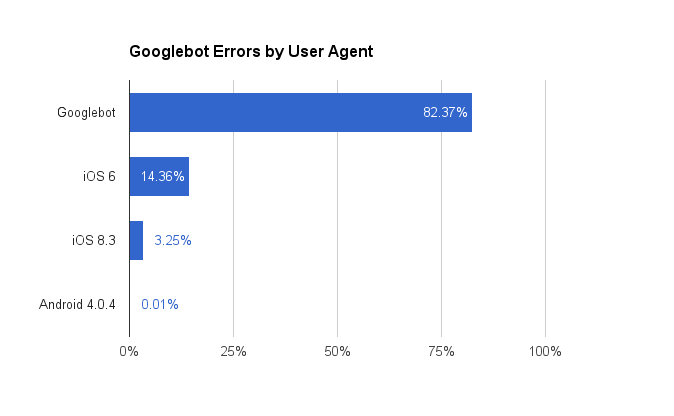
TrackJS Anonymized Data, July 2015
Sometimes things don’t go perfectly during rendering, which may negatively impact search results for your site.
Google Webmaster Central
Google acknowledges the possibility for errors and give some wise advice in their original announcement, such as simplifying JavaScript and degrading gracefully. They also mentioned a debug tool to be made available on Webmaster tools, however we have yet to see it.
The high error-rate of search engine crawlers, combined with the inability to debug Googlebot’s JavaScript errors, paints a scary picture. Subtle JavaScript changes could impact your SEO in ways that are hard to predict or debug.
Isomorphic JavaScript has advanced significantly in the last year. Ember fastboot is a fantastic example of this. But for many use cases, traditional server-rendering is probably easier to build and cheaper to maintain for most SEO use cases.
But if you have that specialized use case and need a client-side rendered SEO app, you’ll need to know when Googlebot is having problems. You’ll probably also want to know when your users are having problems. Let us help with 14 days of free error tracking and bug fixing.
