

The ability to set the status of an error is our most commonly requested feature. Customers want to mark errors as fixed, or one team member wants to let the rest of the team know they are investigating an issue. There’s hundreds of reasons to set the status of an error, and until today it was something users couldn’t do in TrackJS.
Setting Status
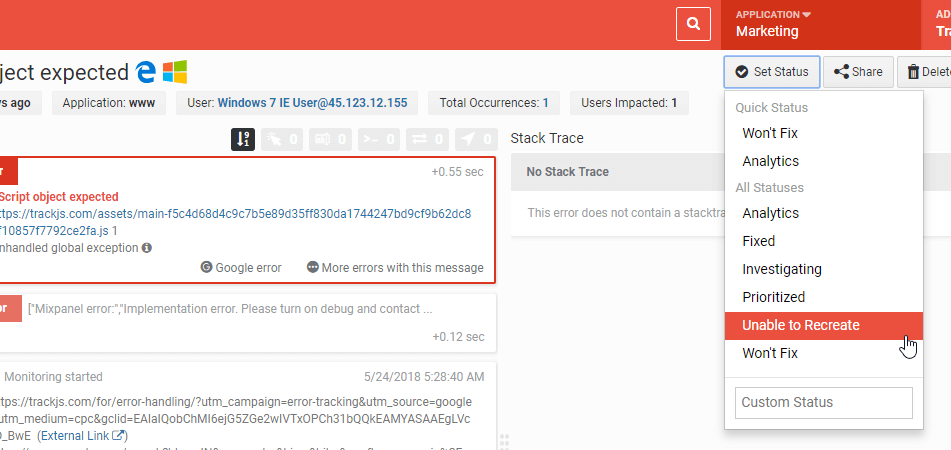
There are two places in the UI where you can set an error’s status currently. The first is from any error details page. When you select a status from the dropdown, or enter a custom value, all errors with that message will receive that status value. This process can take a few seconds for large numbers of errors (more on that below). All newly ingested errors with that message will also receive the status.
You can also set an error’s status from the list screen.
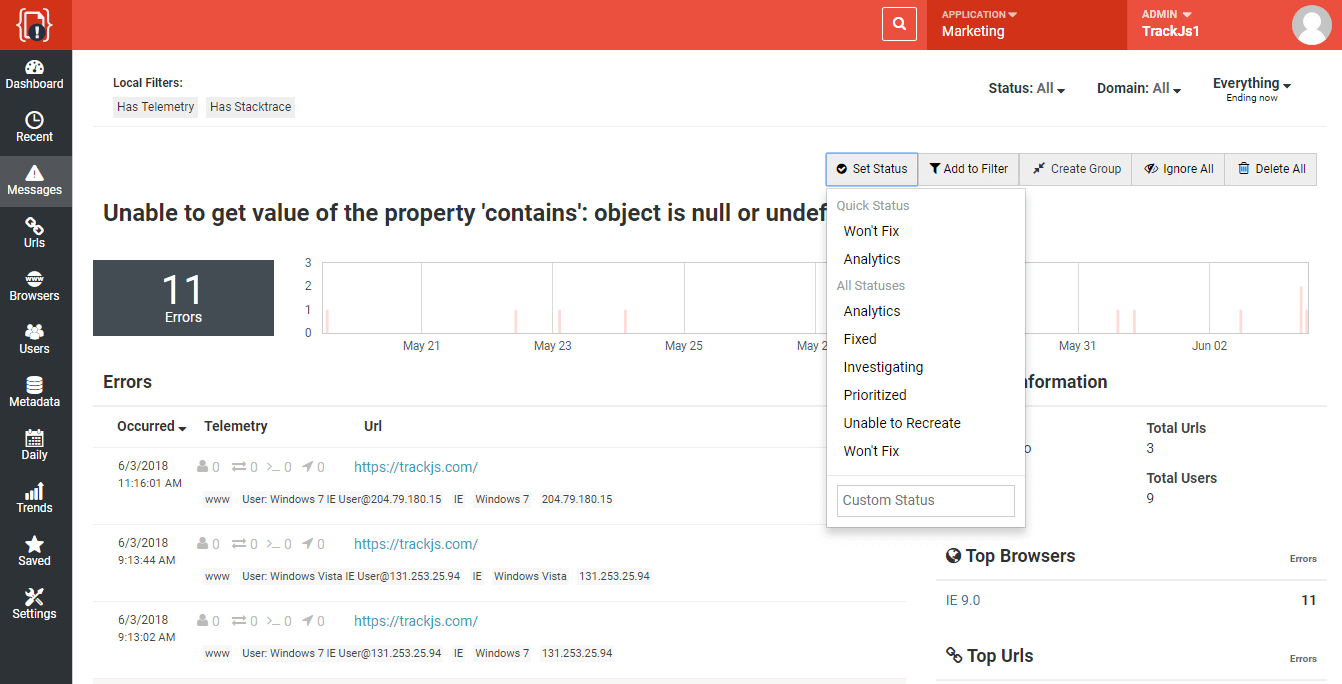
The status dropdown contains a “Quick Status” feature that will show you the last few recently used values. You may also enter your own custom status values at any time.
Viewing and Filtering
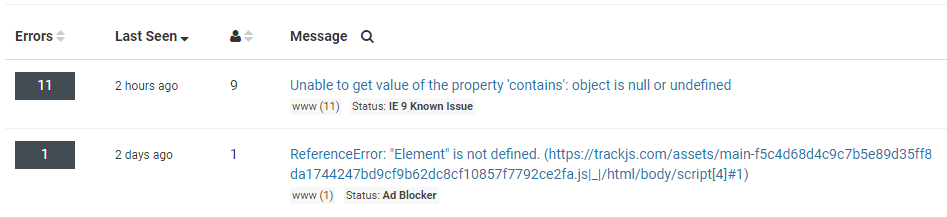
There are a number of pages where you’ll start seeing the status of an error if it contains one. The message grouping screen, the filtered list, recent errors, and the details screen.
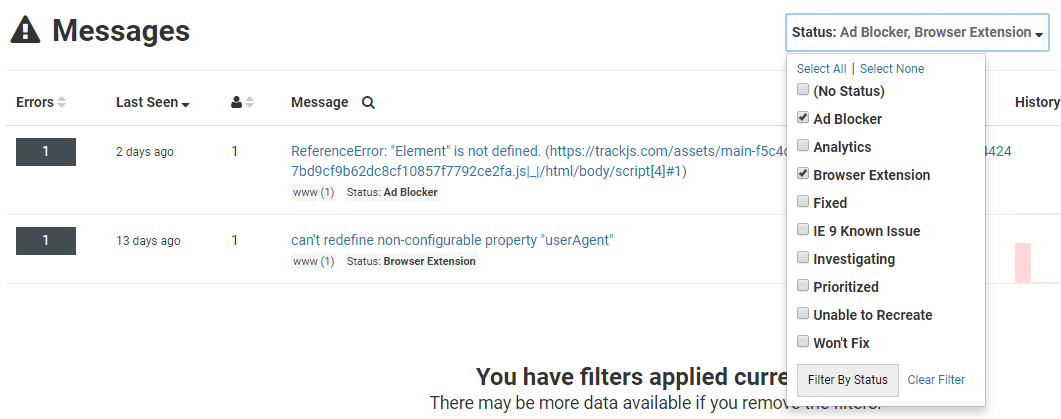
Applying a status is only useful if you can include or exclude those errors from your reports. We have created a new top-level filter where you can pick and choose the statuses you want to see (or remove). This allows very fine grained diagnostics and reporting.
What Took So Long?
This has been a commonly requested feature for years, so you might be wondering, why did it take so long to finally build it? The TLDR is, it’s more complicated than you might think :)
Elasticsearch and Immutability
Our error data is stored in a large Elasticsearch cluster. This lets us slice and dice the data in powerful ways, and give you a great search experience. But that flexibility comes with some limitations. In Elasticsearch, documents are functionally immutable. You can’t modify a document’s properties once it’s been indexed. Or rather, to modify a document you have re-index the entire thing, even if it’s changing a single property.
Many of our customers have millions of errors in their account, and sometimes hundreds of thousands of errors with the same message. Imagine a customer sets a status of “Won’t Fix” on 400,000 errors. We need to retrieve all 400k errors, change the status property, and re-index them. We have beefy dedicated hardware running the cluster, but this is not an instant operation.
Managing the Re-Index Process
Newer versions of Elasticsearch have an “update by query” function that can help with large scale document re-indexes. Essentially the cluster itself will manage the retrieval and re-index of the documents. Unfortunately, the version we use does not have this capability. Even if it did, we wanted a bit more control over the process.
For example, we have a finite number of “workers” that can handle status updates. We don’t want to let one customer monopolize all the re-indexing workers if they are changing dozens of statuses on thousands of errors. So each customer gets their own job queue - and status changes are added to the end of the queue if the previous job is not yet complete.
We also wanted to cap throughput to ensure a single customer couldn’t impact the system’s performance. For now we’re applying a limit of 1,000 errors per customer per second. That means if you update the status of 30,000 errors, it will take approximately 30 seconds for all of those to get the value applied.
Finally, our error ingestion pipeline needed additional smarts to apply a new error’s status correctly when it comes in the front door. We process thousands of events per second, so we had to be doubly sure there was no performance impact along with ensuring the correct behavior.
Next Steps
We’ll be monitoring the system and usage over the next few weeks. We’re curious to see what kind of statuses folks will apply. We’ll also be evaluating how the infrastructure behaves over time. If it proves popular we may introduce the concept of “tagging” as well. If you have any suggestions on how to improve the feature please let us know!
